
Hey there! I’m Robert. Welcome to my newsletter where I share my story of building my AI startup in public, focused on hyper-personalized AI. These newsletters include my reflections on the journey, and topics such as AI, personal growth, CEO-ing, leadership, product, engineering, communication, and more. Subscribe today to follow along.
In 1970, an oxygen tank exploded on Apollo 13.
3 astronauts, 200,000 miles from Earth, in a crippled spacecraft. NASA couldn’t test solutions on the actual vehicle.
So they built virtual replicas of every system on the ground, simulated scenarios in real time, and tested fixes before transmitting them to the crew.
That was the first digital twin.
John Vickers at NASA’s Marshall Space Flight Center wouldn’t coin the term until 2010.
But the concept came from a survival problem: the physical system was too far away and too complex to operate without a queryable model of its current state.
Fifty-five years later, the James Webb Space Telescope couldn’t fit in NASA’s thermal vacuum chamber.
NASA built digital twins to test it. One modeled core temperature (a spike would make the telescope blind). Another tracked the sunshield unfurling, a maneuver with 344 ways to fail.
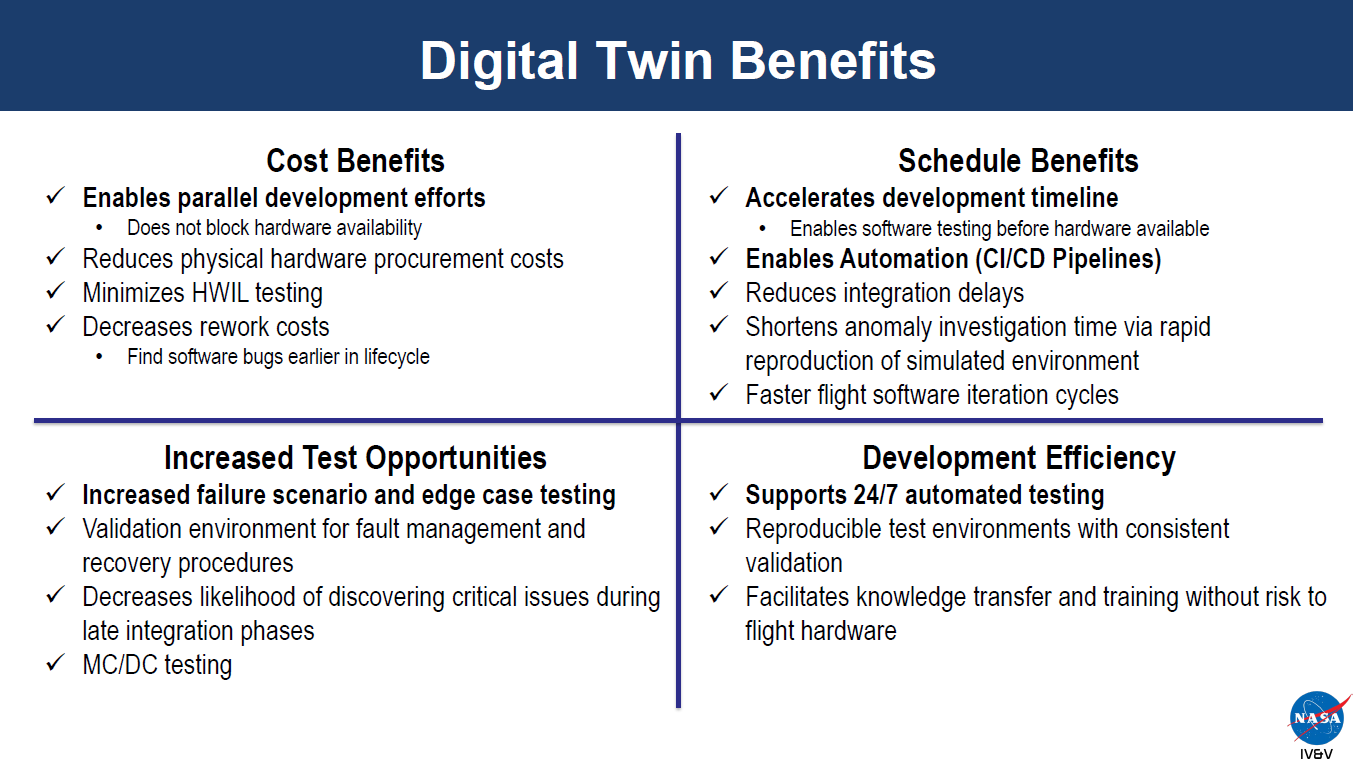
NASA’s JSTAR program quantified what digital twins do for software development: parallel development, CI/CD automation, edge case testing, 24/7 automated validation, knowledge transfer without risk. They call it the “shift left” effect. Testing moves earlier. Time-to-market drops. Product quality rises.
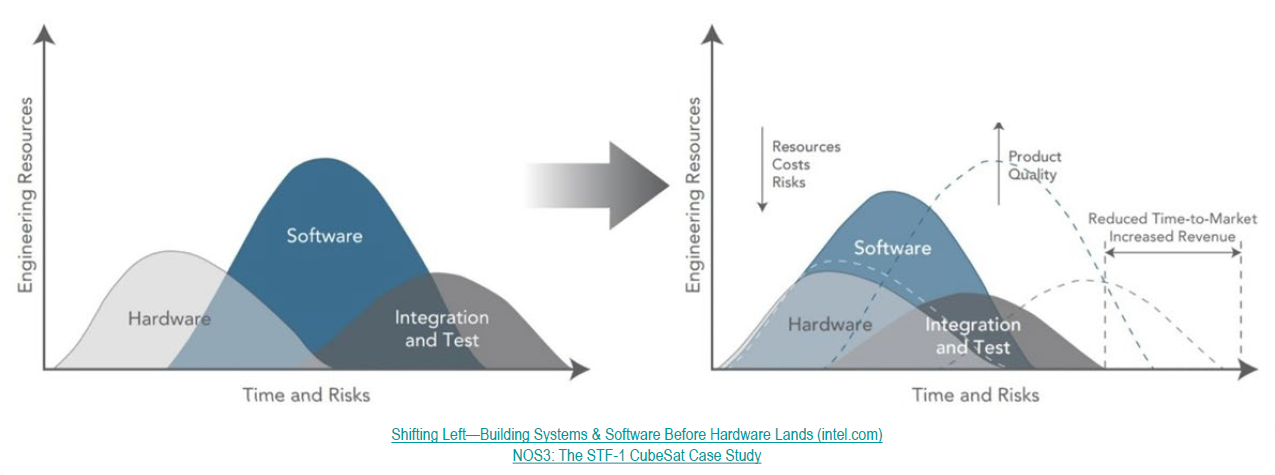
Digital twins started in aerospace. They spread to manufacturing, medicine, and climate modeling.
Now they are making their way into software companies and AI-native teams.
Digital twins are the foundational infrastructure layer for AI-native execution. And we’re building the products that make this real.
What’s Inside This Week:
- 🤖 ALIGN: AI psychosis goes viral, Elon loses, and the YC CEO builds his own agent brain
- 🛠 BUILD: Why AI-native teams need digital twins to 100x their execution
- ✌🏼 CULTURE: The Black Death killed half of Europe’s population. Plant diversity collapsed too. Wait, what?
🤖 ALIGN: This Week in AI
AI psychosis, a verdict, an open-sourced brain, and a staff engineer who still writes his own PR descriptions.
1. Mitchell Hashimoto Warns of “AI Psychosis” Sweeping the Industry
The HashiCorp co-founder posted that companies are operating under an “MTTR is all you need” mentality. Ship bugs because agents will fix them. Millions of views. The HN thread hit 500+ comments. He’s comparing it to the cloud automation reckoning he lived through.
Robert’s Take: This is the junior-vs-senior engineer tension, now industry-wide. Juniors say “ship it, fix it fast.” Seniors say “you don’t understand how complicated this actually is.” The difference in 2026? The juniors have agents backing them up. Doesn’t make them right. Mitchell’s phrase “resilient catastrophe machine” is going to age well.
2. Jury Unanimously Rejects Elon Musk’s Claims Against OpenAI
Three weeks of testimony. Less than two hours of deliberation. The jury found Musk waited too long to sue. He’s calling it a “calendar technicality” and plans to appeal. During the trial, Altman described a meeting at Tesla where Elon spent “a long period of time showing us memes on his phone.” The court reporter had to ask him to repeat “memes on his phone” loudly. LOL.
Robert’s Take: The memes detail is hilarious. Ben Thompson of Stratechery noted that OpenAI came across as a rational actor making defensible decisions the whole way through. The for-profit conversion wasn’t a betrayal. It was a survival decision against Google DeepMind’s war chest. This is wrapped up now. Time to build.
3. GBrain: Y Combinator’s CEO Open-Sourced His Personal Agent Brain
Garry Tan built a self-wiring knowledge graph for his AI agents. 17,888 pages, 4,383 people, 723 companies, 21 autonomous cron jobs. Built in 12 days. The architecture uses typed entity links with zero LLM calls and “dream cycles” where agents enrich knowledge overnight.
Robert’s Take: If the YC CEO still builds custom agent infra, off-the-shelf isn’t good enough yet. The most effective part of the system doesn’t use the most expensive technology. Context infrastructure matters a hell of a lot.
4. A Staff Engineer’s Brutally Honest AI Usage Report for 2026
Sean Goedecke at GitHub wrote a very pragmatic post on agentic coding in 2026 as an update to his 2025 report. In 15 months he went from autocomplete to starting every code change with an agent. But he still refuses to let AI write PR descriptions, ADRs, or Slack messages.
Robert’s Take: Sean draws the line at understanding vs execution. Agents handle execution. He maintains comprehension. That’s the balance Mitchell is worried about losing.
🛠 BUILD: Why AI-Native Teams Need Digital Twins to 100x Their Execution
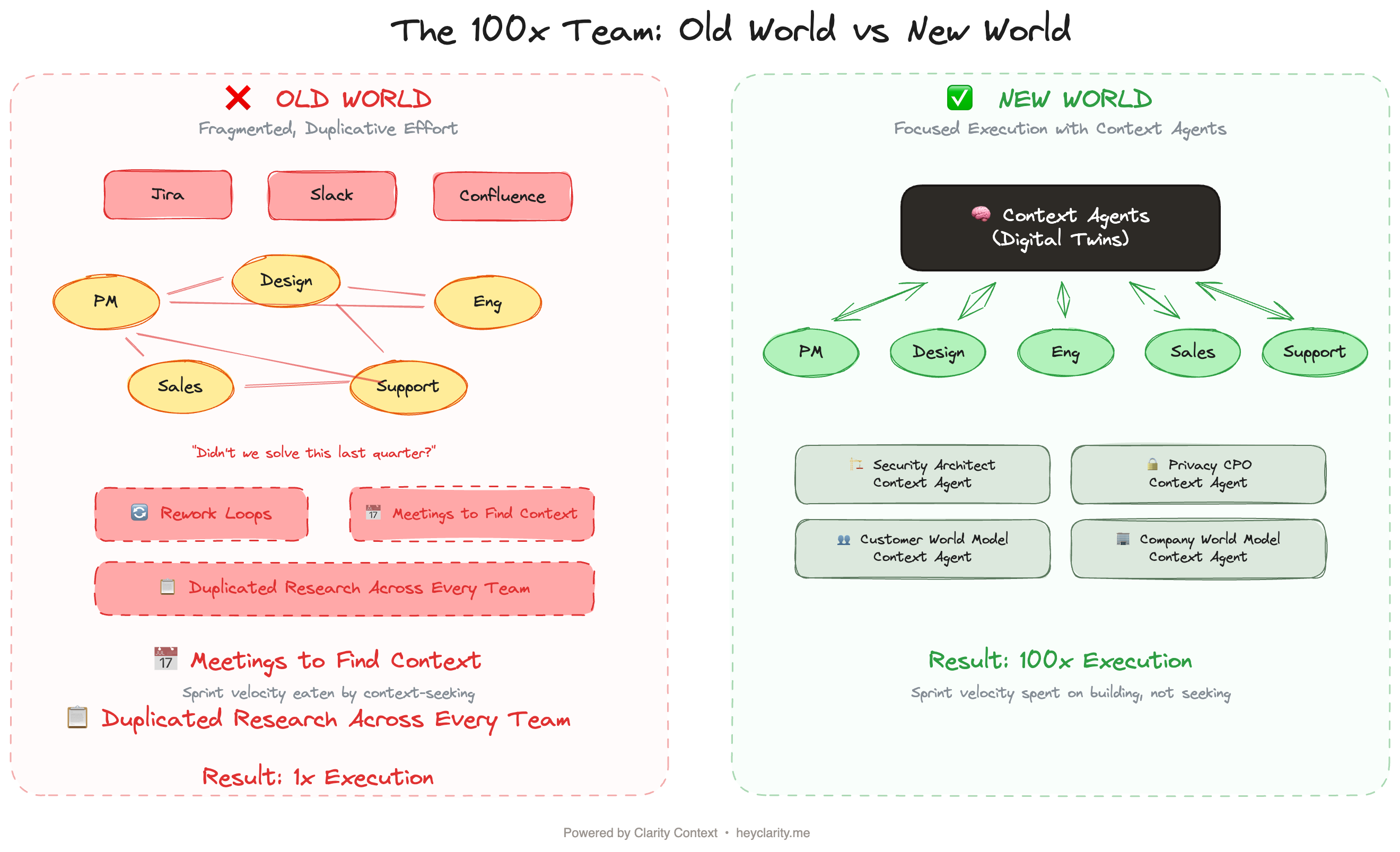
The bottleneck in every AI-native team is not compute. It is not talent. It is not the quality of the models.
The bottleneck is context.
Every time a developer opens a pull request, they start from a degraded version of what the organization already knows. The institutional knowledge that should power their decisions is scattered across Jira tickets, Confluence pages, Slack chats, tribal knowledge, and the heads of people who may have already left the company.
AI gives teams the ability to move at 10-100x speed. But if the optimal context inputs to that AI are fragmented, stale, and unqueryable, you are just moving 10-100x faster in the wrong direction.
Digital twins solve this. They are the infrastructure layer that separates AI-native teams that 100x their execution from teams that just buy more licenses.
The Context Agent
NASA showed us that a digital twin is a living representation of a physical system.
For AI-native teams, I’d sharpen the definition and add a term:
A context agent is a living, queryable digital twin of a person, a customer, a domain, or a system.
Built from real evidence: meeting transcripts, survey data, product analytics, interview recordings, pull request comments. Continuously updated. Confidence-scored.
NOT a persona card in an outdated Confluence wiki that’s stale on arrival, begging to be seen by anybody.
Why does this matter?
Connect a context agent holding validated customer knowledge to an AI agent via MCP.
Boom.
Every function in your company gets on-demand access to the most current version of what the organization knows.
Every team can evaluate their work against those twins:
- Pull requests
- Design prototypes
- Product requirements documents
- User stories
- Sales battlecards
- Marketing lead magnets
That’s now possible.
Jack Dorsey wrote about this in From Hierarchy To Intelligence. I expanded on the concept with my own take on his Company and Customer World Models a few weeks ago, intersecting with digital twins.
The organizational model most companies run was designed for a world where information was expensive to capture and slow to distribute.
The Roman army’s span of control, McKinsey’s 7S framework, the traditional org hierarchy: all of these structures exist to route information from the edge to the center and back.
That routing is now the bottleneck.
In the new world being built right now, context agents replace that information routing with a continuously updated map that every function can read from and write to in real time.
Every hypothesis backed with evidence, queryable by anyone in the org.
Continue reading
Get the full newsletter, free.
Join founders and builders who read Self Aligned every week.
Without digital twins imagine…
A developer touches a compliance-heavy module (legal, payroll, benefits) last modified four months ago by a different team. The decisions from that sprint are scattered across a Jira ticket, a PR comment, and the memory of one engineer who is now on a different project.
The developer makes a reasonable assumption, ships the feature, and two weeks later a compliance issue surfaces that a senior dev with tribal knowledge would have caught in thirty seconds.
If you’re in tech you’ve seen this.
Fragmented, duplicative effort.
With a digital twin
The compliance domain twin, built from every relevant meeting transcript, every regulatory decision, every cross-team dependency discussion, sits in the CI/CD pipeline. Every pull request gets interrogated by that context agent before it merges.
The edge case surfaces automatically. The developer does not need a two-hour refinement meeting to find out what they don’t know. The twin tells them. What used to take a sprint now takes minutes.
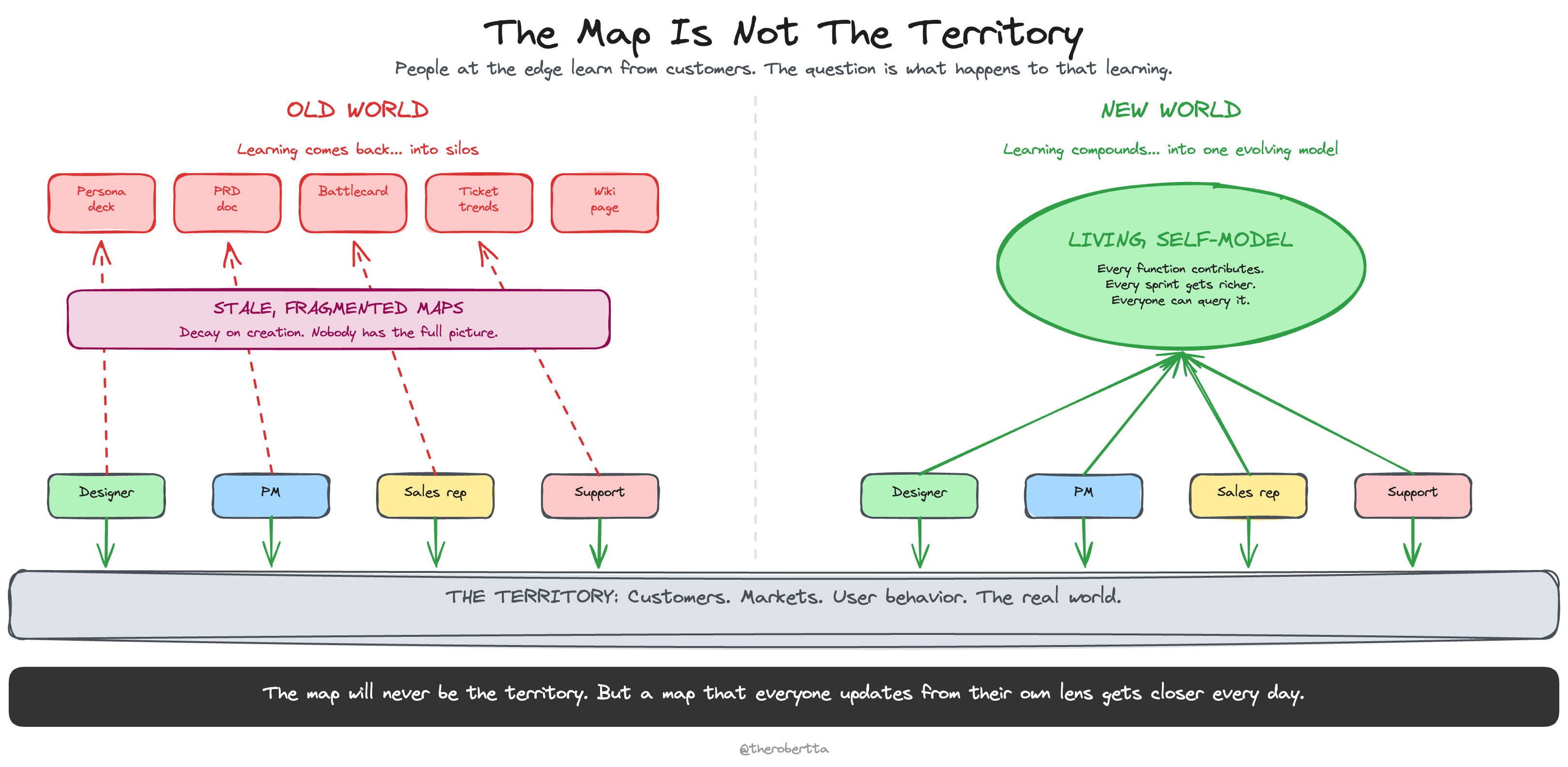
And the twin gets smarter with every PR. Every new piece of evidence feeds back into the model. The context compounds.
The pattern repeats across every function
A researcher painstakingly builds persona cards thoughtfully put together from evidenced research. Hoping the rest of the org will read them. Hoping those hard-earned customer insights will reach the people building the product. They rarely do.
Design teams have thousands of research transcripts in tools like Dovetail, generating zero leverage. The distribution mechanism is a PowerPoint deck emailed to a wiki nobody reads.
That’s not the designer’s fault. We’re wasting their expertise on internal marketing instead of letting them map the territory of the market.
Context agents fix the distribution problem. Every customer interview becomes a queryable asset. Every sales call updates the customer world model.
The organization compounds its learning instead of losing it.
So how do you get yourself some context agents?
Good news.
Build in Public: Clarity Context
We’ve been building Clarity API as a developer-focused digital twin tool for B2B enterprise.
I’ve wanted to make digital twins more accessible to everyone instead of requiring us to implement for you.
That’s happening now.
Clarity Context sits on top of Clarity API and turns your company’s scattered knowledge into context agents.
A Chief Privacy Officer context agent that catches GDPR violations in pull requests before they merge. No more meeting scheduling juggling hell to get a privacy review.
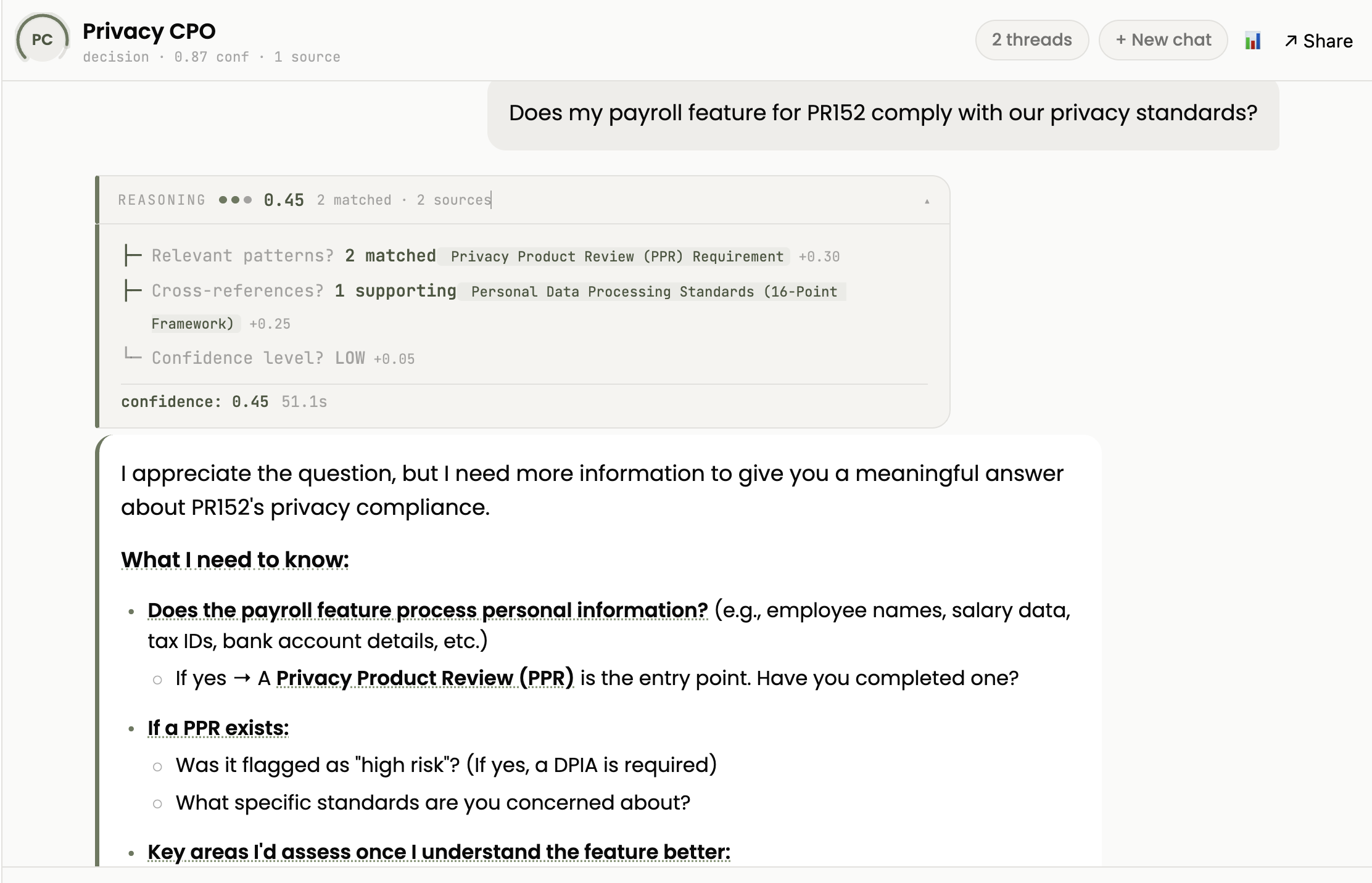
An Architecture context agent that tells the new developer why you chose Redis over Memcached, before they make the wrong assumption. Don’t have to have the dreaded and slow Architecture Review Board where people talk over each other and nothing moves forward.
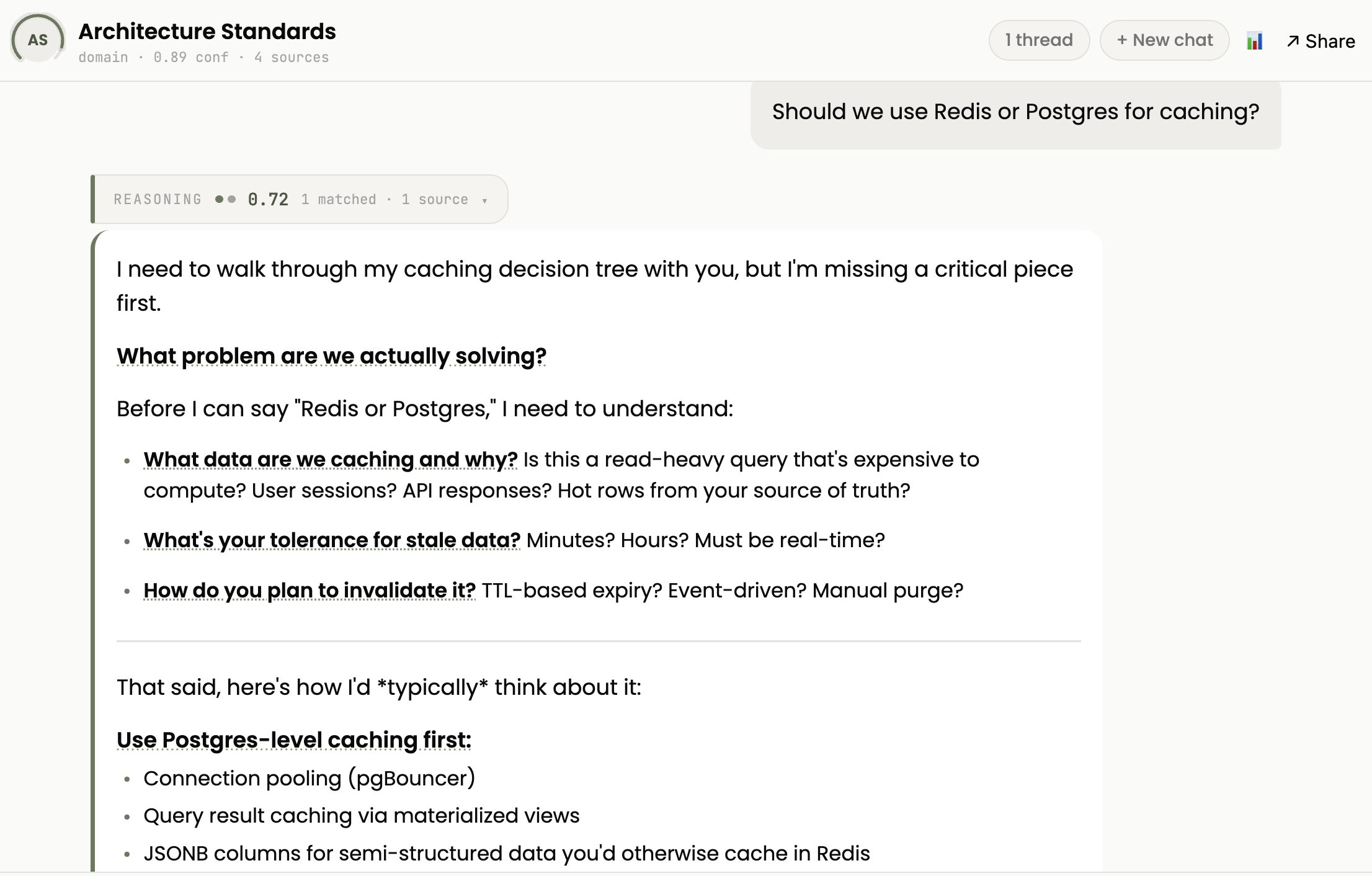
This is the product I wished existed when I was Chief Product Architect at Dayforce. We had 1,600+ engineers and the tribal knowledge problem was constant.
We burned entire sprints on rework that a queryable twin would have prevented in seconds.
Here’s what this looks like in practice, dogfooding Clarity myself:
- I will have a customer meeting getting feedback on a prototype
- I will take the customer meeting transcript and upload it to Clarity which…
- Clarity extracts a structured digital twin with belief statements and confidence scores
- Clarity cross-checks it against other stakeholder and domain twins
- I then connect it to a code generation agent via MCP
- I then send that same customer a high-fidelity prototype within 15 minutes of the call ending
Minutes, not days.
Compliance questions answered at 3am, in any time zone.
No two-week meeting delays. No “let me find the person who knows.” Everyone operates from the same ground truth.
The stories that took 1 scrum team 10 weeks can be completed by 1 person in 3-4 days. But only when the context infrastructure supports that velocity.
Without it, you are 100x-ing AI slop.
The compounding advantage
The companies that figure this out first will have a structural advantage that compounds. Every customer interaction makes the twin smarter.
Every sprint makes the engineering domain twin more accurate.
Teams still operating with fragmented, static knowledge artifacts will be competing against organizations where the AI has a living representation of everything the company knows.
Want your own Clarity Context Agents?
Check out heyclarity.me
Launching next week, I am so excited! 😁
✌🏼 CULTURE: When Humans Disappeared, Nature Didn’t Recover
Every week I try to learn something new about our vast world, and I share it here. Sometimes it’s related to the main article, sometimes it’s just something cool. Enjoy.
When the Black Death killed roughly half of Europe’s population in the 14th century, plant biodiversity collapsed too. Not recovered. Collapsed.
You would expect the opposite. Fewer humans, more nature. Forests grow back, meadows return, ecosystem bounces.
The data says otherwise. Centuries of agriculture, grazing, and land management had created ecological niches that wild plants depended on. Meadows existed because farmers mowed them. Wildflowers thrived because livestock grazed competing species. The humans were part of the system. When they disappeared, the complexity they maintained disappeared with them.
Same thing happens in companies. Your senior architect leaves. The system doesn’t self-heal. The tribal knowledge they carried was load-bearing. The codebase decays. The edge cases they caught, the design decisions they remembered, gone.
Documentation is a meadow that nobody mows. It goes stale the week after someone writes it.
The real answer is a living system.
Keep building, Robert
📖 Read the interactive version →
Experience this newsletter with scrollytelling animations, data visualizations, and an immersive reading experience on the web.
Liked this article?
💚 Click the like button.
Feedback or addition?
💬 Add a comment.
Know someone that would find this helpful?
🔁 Share this post.
Follow me for more on building better AI and building better with AI:
Sources
[1] NASA Biological & Physical Sciences Division, Why does the world (and NASA) need digital twins?, NASA, 2025. Link
[2] NASA IV&V, JSTAR Digital Twins, NASA, 2025. Link
[3] Elon Musk loses court battle against Sam Altman and OpenAI, CNBC, 2026. Link
[4] Garry Tan, GBrain: Garry’s Opinionated OpenClaw/Hermes Agent Brain, GitHub, 2026. Link
[5] The Black Death’s counterintuitive effect: As human numbers fell, so did plant diversity, Phys.org, 2026. Link
[6] Jack Dorsey, From Hierarchy To Intelligence, Sequoia Capital, 2026. Link